



题目背景
深度学习模型训练可以被描述为一个有向无环的计算图的执行。计算图中的节点叫做 Operator。节点之间有方向的边代表 Operator 之间的依赖关系,这个依赖关系是由深度学习模型确定的,即一个 Operator 的输出(Tensor)是另一个 Operator 的输入,那么在计算图中就需要有一条射线连接两个 Operator。
一个 Operator 可以有多个 Tensor 输入或者多个 Tensor 输出。Operator 本身有计算代价,通常是计算 Operator 所需要的时间。Operator 可以运行在多种设备上。同一个设备下在任意时间点只能最多 N 个 Operator 并发执行,如果 N=1,意味着这个设备下执行Operator 只能串行。
执行在不同设备下的 Operator,可以并发执行。
计算图的起始节点可以有多个,结算图的终止节点也可以有多个,整个计算图的节点都执行完算作深度学习模型的一次迭代(Iteration)。
此处用一张 DAG 解释以上概念
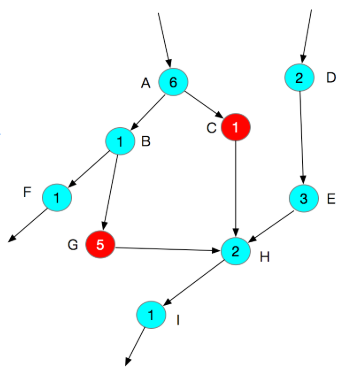
图中有两个颜色的节点,代表在不同设备上执行的 Operator,节点中的数字代表 Operator 的计算代价。假设每个设备只允许一个并发,那么可以给出若干个符合拓扑序的执行顺序,例如 ABCFGDEHI,执行代价为 16,也可以是 DEACBFGHI,执行代价为 19。
题目
本题假定计算图中的 Operator 有两种类型,一种是计算 Operator,一种是通信 Operator。计算 Operator 在 AI 芯片上执行,通信 Operator 主要在网络通信设备上执行。
通信 Operator 最多有 3 个并发,计算 Operator 最多有 1 个并发。计算图的总节点数不超过十万。要求实现一个函数,给定任意计算图,返回一个符合计算图拓扑排序的 Operator 执行顺序,使得整体计算代价尽量小。
数据
计算图来源:基于一些计算图生成规则(规则不公开)随机生成的计算图。
比赛开始时,会提供 100 个根据赛题系统生成规则随机生成的计算图,以及 10 个真实深度学习模型转换得到的计算图,方便选手进行调试和观察规律。
赛制
三阶段综合排名制,第一阶段为热身阶段,主要目的是熟悉基本工具,不计分。第二阶段选手的平均计算代价占最终得分 10%,第三阶段选手的平均计算代价占最终得分的 90%。
第一阶段:选手能够根据比赛平台提供的几个计算图示例,通过程序或者肉眼观察的方式给出计算图的执行顺序,并提交到 Timeline 系统生成 Timeline 文件。Timeline 文件可以用于在 Chrome 浏览器进行可视化,代表计算图的执行时间线。Timeline 在整个比赛都可以提交,推荐选手在 30 分钟内完成。
第二阶段:计算图数目 100,由赛题系统生成,提交截止时间是比赛开始后 2.5 小时,到提交时间截止后,系统会运行选手最后一次提交的 CPP 文件作为选手的算法,10 分钟内给出榜单。
第三阶段:计算图数目 10000,由赛题系统生成,提交截止时间是比赛开始后 6 小时,随后半小时内系统会给出选手最终排名,比赛结束。
评分规则
评估系统会对选手提交的算法进行综合评估,在赛题系统随机生成的题目上进行打分。赛题系统生成题目的方式会参考真实深度学习模型的一些统计指标,通过系统规则生成,这部分规则对选手不公开。
得分计算方法:赛题系统会提供基线算法对赛题进行打分,基线算法来源于百度开源深度学习框架飞桨中的图调度引擎的基础算法。选手提交的算法,相对于基线算法的提升会作为选手的最终得分,得分计算公式如下:
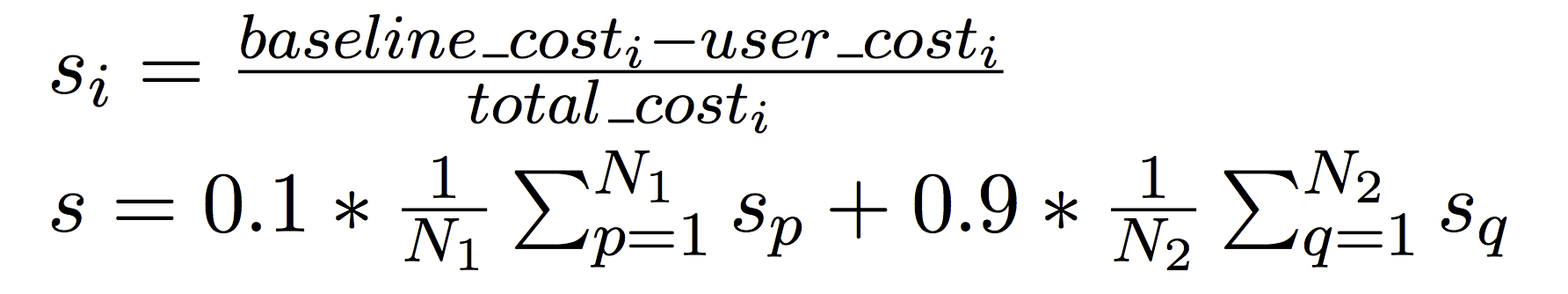
其中,baseline_cost
为飞桨的基础调度算法得到计算代价,total_cost 为计算图所有节点的计算代价总和,user_cost 为选手的算法得到的计算代价。
关于计算代价:选手提交的程序会被编译为动态库与系统联编,并在集群环境中进行大规模分布式计算,并得到每张图的计算代价值。
运行超时的计算代价:在集群环境中,我们会为每次运行设置一个超时时间,长度为 10s。如果选手提交的程序在同一张计算图下超时达到3次,我们认为选手提交的程序运行速度过慢,并给超时的计算图一个超时代价。超时代价为当前计算图所有计算节点计算代价总和。
内存超过系统限制的计算代价:系统限制选手的算法在赛题运行过程中,单个计算图执行不能超过 16GB 内存,如果内存超限,系统会给出以内存超限代价返回,内存超限代价为当前计算图所有计算节点计算代价总和。
其他系统类错误:运行过程中遇到程序异常退出,视为选手代码有 Bug,给出异常错误的计算代价,异常错误的计算代价为当前计算图所有计算节点计算代价总和。
排名计算方法:选手的算法打分会根据上述给定的公式进行计算,系统会根据选手的打分进行排名,评分越高排名越靠前。如果评分相同,则根据算法的执行时间进行排序。算法的执行时间会在选手得分相同的情况下,在公平环境下重新运行得到。
程序接口
编程语言采用 C++11 标准,编译器为 gcc 5.4,不允许使用 C++ 基础库以外的库,编译命令g++ -O3 -lpthread。
计算图的表示格式:计算图通过一组表达式构成,例如在题目介绍部分展示的计算图是通过下面这组表达式构成:
B=A
C=A
G=B
F=B
E=D
H=C#E#G
I=H
比赛中,每个计算图相关的表达式以及节点的详细信息存放在单独的文件夹下。比如在 task_example 中,这些表达式存放在 expressions.txt 文件中, 同时,每个节点的详细信息(比如权重,颜色等)存放在 nodes 文件夹下,节点所在文件的名字为 node_x.txt, 其中 x 表示颜色信息。在 task_example 中,计算图中的节点有两种颜色,这两种颜色所对应的节点信息分别存放在 node_0.txt 和 node_1.txt 中。
├── task_example
│ ├── expressions.txt
│ └── nodes
│ ├── node_0.txt
│ └── node_1.txt
选手需要实现的接口:std::vector<std::string> execution_order(const std::string& node_path);。
execution_order 的输入为计算图表达式和节点所在的路径,输出为执行所有节点的 topo.txt 序列,输出的形式为节点的 name。
 Alca
Alca Amber
Amber Belleve Invis
Belleve Invis Chensiting123
Chensiting123 Edward_mj
Edward_mj Fotile96
Fotile96 Hlworld
Hlworld Kuangbin
Kuangbin Liyaos
Liyaos Lwins
Lwins LYPenny
LYPenny Mato 完整版
Mato 完整版 Mikeni2006
Mikeni2006 Mzry
Mzry Nagatsuki
Nagatsuki Neko13
Neko13 Oneplus
Oneplus Rukata
Rukata Seter
Seter Sevenkplus
Sevenkplus Sevenzero
Sevenzero Shirleycrow
Shirleycrow把这些素数乘起来…….. …. ” …") Vfleaking
Vfleaking wangzhpp
wangzhpp Watashi
Watashi WJMZBMR
WJMZBMR Wywcgs
Wywcgs XadillaX
XadillaX Yangzhe
Yangzhe 三途川玉子
三途川玉子 About.me
About.me Vijos
Vijos
