



Problem D. Maximum Waterfall
Brief description:
。。给定一颗 “瀑布”。。落到下面的水量为重叠部分的宽度。。u -> v 的条件是中间没有阻隔。。(不存在 u -> w, 同时 w -> v 。。。
。。。问可以接多少水。。
Tags:
扫描线、动态规划
Analysis:
。很直接的扫描线处理出 dag 然后接 dp。。当然要写的快的话最好把这两个过程结合在一起。。。
。。扫描线的过程类似 SGU 319. Kalevich Strikes Back 。。。
。。和那题一样。。这题也可以直接用 set<int> 爆。。
//}/* .................................................................................................................................. */
const int N = int(1e5) + 9;
typedef pair<int, PII> rec;
#define h fi
#define l se.fi
#define r se.se
set<PII> T; rec A[N];
int f[N], stk[N], nn;
int n, t;
int overlap(int a, int b){
return min(A[a].r, A[b].r) - max(A[a].l, A[b].l);
}
bool stem(int a, int b, int c){
return A[a].h > A[b].h && A[b].h > A[c].h && overlap(a, c) && overlap(a, b) && overlap(b, c);
}
int main(){
#ifndef ONLINE_JUDGE
freopen("in.txt", "r", stdin);
//freopen("out.txt", "w", stdout);
#endif
RD(n, t); REP(i, n) RD(A[i].h), RDD(A[i].l, A[i].r);
A[n++] = MP(0, MP(-INF, INF)), A[n++] = MP(t, MP(-INF, INF));
#undef h
#undef l
#undef r
#define h A[i].fi
#define l A[i].se.fi
#define r A[i].se.se
T.insert(MP(-INF, 0)), T.insert(MP(INF, 0));
sort(A, A+n), f[0] = 2*INF; FOR(i, 1, n){
set<PII>::iterator ll = T.lower_bound(MP(l, INF)), rr;
for (rr=--ll,nn=0;rr->fi<r;++rr) stk[++nn]=rr->se;
if(ll->fi!=l) ++ll; stk[nn+1]=0;
T.erase(ll, rr), T.insert(MP(l, i));
if (rr->fi != r) T.insert(MP(r, stk[nn]));
//ECH(it, T) cout << it->fi << ", "; cout << endl;
REP_1(ii, nn){
if (stem(i, stk[ii-1], stk[ii]) || stem(i, stk[ii+1], stk[ii])) continue;
checkMax(f[i], min(f[stk[ii]], overlap(i, stk[ii])));
}
}
OT(f[n-1]);
}
Problem E. Prime Matrix
Brief description:
In this problem we have an n × m rectange. Each unit midpoint is connected with a segment to some other midpoint not on the same side of the rectangle. We can change the order of the columns and rows, but the segments must remain attached to their midpoints. We should find such a rearrangement that no two segments intersect, or tell that there is no solution.
。。解锁游戏。。给定一个方阵。。然后上下左右每条边的中点都和一个不在同一边的中点相连。。
要求给一组行和列的排列。。。使得重排后。。新的图中。。不存在交点。
。任意给出一种合法方案或判断无解。。
Tags:
恶模拟、置换循环节、循环同构、字符串最小表示
Analysis:
There are overall 6 types of segments that connect the sides:
- left-top;
- top-right;
- right-bottom;
- bottom-left;
- left-right;
- top-bottom;
If there are both left-right and top-bottom segments, there is no solution. Otherwise there remain only 5 types of segments. Without loss of generality suppose there are no left-right segments. Let’s take a closer look at what should the end picture of the rectangle be:

All left-top segments should be at the left top corner connecting positions (L,i) and (T,i), otherwise they surely would cross some other segment. Similarly must be positioned top-right, right-bottom, bottom-left segments. Finally, all top-bottom segments should be parallel. We also observe that the number of left-top segments must be equal to the number of right-bottom segments and the number of top-right segments should be equal to the number of bottom-right segments. Thus the important observation: the picture of the end arrangement is unique and can be determined from the input simply by counting the number of segments of each type.
。。。从以上主要是在说。。如果可以解锁的话。。解锁后的图形是固定的。。。
Next we define a cycle to be the sequence of segments, where the second midpoint of some segment in the cycle is equal to the first midpoint in the next segment in the cycle. In the given example there are two such cycles (but the direction of each cycle actually matters):

Then we observe that the set of the cycles does not change with any permutation by the definition of the cycle. We can make a sketch of the solution: we should find the cycle sets in the given arrangement and in the end arrangement, and compare them for equality.
At this point we actually find all the cycles in both arrangements. There are only two types of cycles:
- (left-top) (top-right) (right-bottom) (bottom-left);
- other cycles.
We can easily check whether the sets of first type cycles match, since the length of such cycles is 4. If they match, we rearrange the columns and rows involved to match the end arrangement.
How to compare the remaining cycles. Consider a following example:
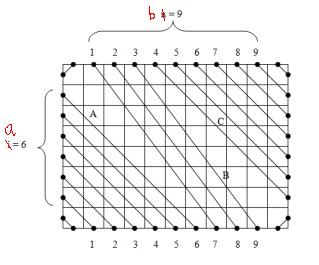
Let the difference in the number of left-top and left-bottom segments be i, and this number plus the number of top-bottom segments s. If we enumerate the midpoints as in the figure, we can see that each top midpoint i is connected to the bottom midpoint (i+a)%b (top-right segments continue as corresponding left-bottom segments). Thus we can describe it as a permutation
\[\left(\begin{array}{ccc} 0 & 1 & \ldots & b-1 \\0+a & 1+a & \ldots & (b-1)+a \end{array} \right)\]
(。。。官方题解这里的记号有点乱。。上图我重新标记过。)
。。至此全部都在集中分析 cycle —— 这个 rearrange 过程的不变量。。。这部分也是这个题最困难的地方。(我认为。。
。。一共只有两类 cycle。。 第一类 cycle 出现在四个角。。长度固定为。。。 重排之后距离每个角的位移也可以固定。。
。。第二类 cycle 则将会形成上面这个置换的所有循环节。。。
Our cycles correspond to the cycles in this permutation, with top-right segment continuation to left-bottom segment corresponding to the case where permutation cycle element decreases. It is known that the number of such permutations is \(gcd(a, b)\( and their length is \(b/gcd(a, b)\(. So all these cycles have the same length. Denote the remaining segment types as some letters (in picture A, B, C). Then not only the length, but the strings describing the cycles are also the same, but can be shifted cyclically (here the direction of the cycles also is important). Besides, we know this string from the correct arrangement cycle. Thus we need to compare all the remaining given arrangement cycle strings to this string, considering cyclic shifts as invariant transformations. For each string this can be done in linear time, for example, using the Knuth-Morris-Pratt algorithm. When we find a cyclical shift for each cycle, we can position its relevant columns and rows according to the end arrangement.
。。。
。。算法的核心就是处理出这两类循环节。。判断是否循环同构即可。。(。。。注意还要枚举一下 2 个方向。。。
bool solve() {
REP(i, n) if(!vis[i]){
VI cyc; dfs(i, link, cyc);
if (iscyc1(cyc)) cyc1.PB(cyc);
else cyc2.PB(cyc);
}
return gao1(), gao2();
}
int main(){
#ifndef ONLINE_JUDGE
freopen("in.txt", "r", stdin);
//freopen("out.txt", "w", stdout);
#endif
REP_C(i, n = RD(r) + RD(c)){
char s1, s2; RC(s1, s2); int x1 = id(s1, RD()-1), x2 = id(s2, RD()-1);
link[x1] = x2, link[x2] = x1;
}
if (!solve()) puts("No solution");
else {
REP(i, r) OT(ans_r[i]+1); puts("");
REP(i, c) OT(ans_c[i]+1); puts("");
}
}
。一轮 dfs 之后。。就可以得到两组循环节。。然后先去处第一类循环节产生的角落。。然后判断第二类循环的合法性即可。。。
。。建立编号系统。。需要一组互逆函数。。。
。pair
inline int id(char c, int x) { // 编号
if (c=='L') return x;
if (c=='T') return x + r;
if (c=='R') return x + n;
return x + n + r;
}
inline pair<char, int> di(int x) { // 逆编号。。
return x < n ? x < r ? MP('L', x) : MP('T', x-r) : x < n + r ? MP('R', x-n) : MP('B', x-n-r);
}
0 1 2 3 4 0 0 1 1 2 2 0 1 2 3 4
inline int cp(int x) { // 对面
return x < n ? x + n : x - n;
}
。。这样编号的话对面也会很容易求。。
void gao1(){
REP(i, SZ(cyc1)){
const VI& cyc = cyc1[i];
if (iscyc1(cyc) == 1){
ans_r[i]=di(cyc[0]).se, ans_r[r-1-i]=di(cyc[3]).se;
ans_c[i]=di(cyc[1]).se, ans_c[c-1-i]=di(cyc[5]).se;
}else{
ans_r[r-1-i]=di(cyc[0]).se, ans_r[i]=di(cyc[3]).se;
ans_c[i]=di(cyc[1]).se, ans_c[c-1-i]=di(cyc[5]).se;
}
usd[id('L', i)] = usd[id('L', r-1-i)] = 1;
usd[id('R', i)] = usd[id('R', r-1-i)] = 1;
usd[id('T', i)] = usd[id('T', c-1-i)] = 1;
usd[id('B', i)] = usd[id('B', c-1-i)] = 1;
}
}
。。第一类循环节可以任意打乱顺序。。。主要的目的是用 usd 记录在这个阶段挖去了哪些点。。
void gen_dir(){
VI a1, a2;
DWN(i, r, 0) if(!usd[i]) a1.PB(i);
REP(i, c) if(!usd[r+i]) a1.PB(r+i);
REP(i, r) if(!usd[n+i]) a1.PB(n+i);
DWN(i, c, 0) if(!usd[n+r+i]) a1.PB(n+r+i);
REP(i, r) if(!usd[i]) a2.PB(i);
REP(i, c) if(!usd[n+r+i]) a2.PB(n+r+i);
DWN(i, r, 0) if(!usd[n+i]) a2.PB(n+i);
DWN(i, c, 0) if(!usd[r+i]) a2.PB(r+i);
REP(i, SZ(a1)) dir1[a1[i]] = a1[SZ(a1)-i-1];
REP(i, SZ(a2)) dir2[a2[i]] = a2[SZ(a2)-i-1];
}
bool gao2(int *dir) {
CPY(vis, usd); VVI target, start;
REP(o, SZ(cyc2)){
VI &arr = cyc2[o];
dump(arr, tmp); shift(arr, lex_smallest_head(tmp, SZ(arr)));
start.PB(arr);
}
REP(i, n) if(!vis[i]){
VI arr; dfs(i, dir, arr);
dump(arr, tmp), shift(arr, lex_smallest_head(tmp, SZ(arr)));
target.PB(arr);
}
#define n SZ(start)
#define m SZ(start[i])
if (n != SZ(target)) return 0;
SRT(start), SRT(target); REP(i, n) if(m != SZ(target[i])) return 0;
REP_2(i, j, n, m){
int s = start[i][j], t = target[i][j]; pair<char, int> ss = di(s), tt = di(t); if (ss.fi != tt.fi) return 0;
tt.se[ss.fi == 'L' || ss.fi == 'R' ? ans_r : ans_c] = ss.se;
}
#undef n
#undef m
return 1;
}
bool gao2(){
return gen_dir(), gao2(dir1)||gao2(dir2);
}
。。。处理第二类循环节。。先要用 usd 数组生成两组方向序。。(。。注意之前的编号系统。。这一步很容易写错。。
。。之后判断是否有一个合法即可。。。判断合法的过程主要是字符串的最小表示。。然后挨个比较。。
。。。kelvin 的代码。。这一步还先判断了一下字符串 hash 。。但实际意义似乎不大。。( ⊙ o ⊙ )。。。)。。
External link:
Codeforces Round #165 (Div. 1)
Codeforces Round #165 Tutorial
http://roosephu.github.com/2013/02/01/CF-165/
 Alca
Alca Amber
Amber Belleve Invis
Belleve Invis Chensiting123
Chensiting123 Edward_mj
Edward_mj Fotile96
Fotile96 Hlworld
Hlworld Kuangbin
Kuangbin Liyaos
Liyaos Lwins
Lwins LYPenny
LYPenny Mato 完整版
Mato 完整版 Mikeni2006
Mikeni2006 Mzry
Mzry Nagatsuki
Nagatsuki Neko13
Neko13 Oneplus
Oneplus Rukata
Rukata Seter
Seter Sevenkplus
Sevenkplus Sevenzero
Sevenzero Shirleycrow
Shirleycrow把这些素数乘起来…….. …. ” …") Vfleaking
Vfleaking wangzhpp
wangzhpp Watashi
Watashi WJMZBMR
WJMZBMR Wywcgs
Wywcgs XadillaX
XadillaX Yangzhe
Yangzhe 三途川玉子
三途川玉子 About.me
About.me Vijos
Vijos

Leave a Comment